

EpilepsyLLM: Fine-tuning large language models for Japanese epilepsy knowledge representation

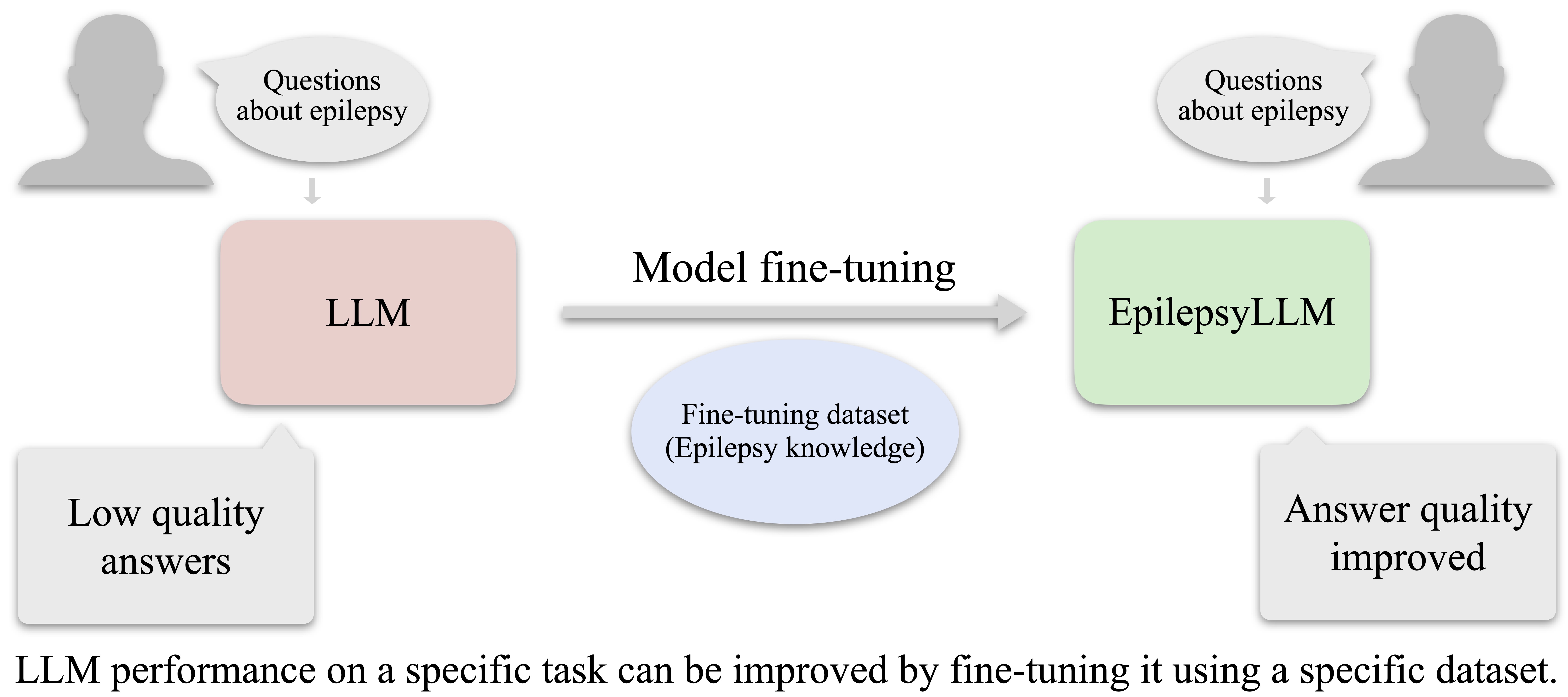
With massive training data and sufficient computing resources, large language models (LLMs) have demonstrated impressive capabilities. These models can rapidly respond to questions in almost all domains and are capable of retrieving, synthesizing, and summarizing information. The capabilities demonstrated by LLMs can enhance our livelihood and foster innovation. Nonetheless, in some professional domains, the focus is not only on response speed but also on higher requirements for response reliability. For example, in the medical domain, the reliability of information provided by the model poses a great risk to subsequent diagnosis and treatment, especially when the language is not English. In specific domains, domain-specific knowledge can be used to refine pre-trained LLMs to improve their performance in specific tasks. In this study, we aimed to build an LLM for epilepsy, called EpilepsyLLM. We constructed an epilepsy knowledge dataset in Japanese for LLM fine-tuning, and the dataset contained basic information on epilepsy, common treatment methods and drugs, and important notes on patients’ lives. Using the constructed dataset, we refined several different pre-trained models with supervised learning. In the evaluation process, we applied multiple metrics to measure the reliability of the LLMs’ output. The experimental results highlighted that the fine-tuned EpilepsyLLM can provide more reliable and specialized epilepsy responses.
- Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. In: 31st Conference on Neural Information Processing Systems (NIPS 2017). Vol. 30. United States; 2017.
- Radford A, Narasimhan K, Salimans T, Sutskever I. Improving Language Understanding by Generative Pre- Training. OpenAI Blog; 2018.
- Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I. Language Models are Unsupervised Multitask Learners. Vol. 1. OpenAI blog; 2019. p. 9.
- Brown T, Mann B, Ryder N, et al. Language models are few-shot learners. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS). Vol. 33. United States: Cornell University; 2020. p. 1877-1901.
- Ouyang L, Wu J, Jiang X, et al. Training Language Models to Follow Instructions with Human Feedback. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS). Vol. 35. 2022. p. 27730-27744.
- OpenAI, Achiam J, Adler S, et al. GPT-4 Technical Report. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2303.08774
- Touvron H, Lavril T, Izacard G, et al. LLaMA: Open and Efficient Foundation Language Models. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2302.13971
- Hoffmann J, Borgeaud S, Mensch A, et al. Training Compute-Optimal Large Language Models. arXiv. Preprint posted online 2022. doi: 10.48550/arXiv.2203.15556
- Narang S, Chowdhery A. Pathways Language Model (Palm): Scaling to 540 Billion Parameters for Breakthrough Performance. Google AI Blog; 2022.
- Zong H, Wu R, Cha J, et al. Large language models in worldwide medical exams: Platform development and comprehensive analysis. J Med Int Res. 2024;26:e66114. doi: 10.2196/66114
- Brin D, Sorin V, Konen E, Nadkarni G, Glicksberg BS, Klang E. How Large Language Models Perform on the United States Medical Licensing Examination: A Systematic Review. medRxiv. Preprint posted online September 3, 2023. doi: 10.1101/2023.09.03.23294842
- Gilson A, Safranek CW, Huang T, et al. How does ChatGPT perform on the United States medical licensing examination (USMLE)? The implications of large language models for medical education and knowledge assessment. JMIR Med Educ. 2023;9(1):e45312. doi: 10.2196/57594
- Kim Y, Park C, Jeong H, et al. MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS). Vol 37. 2024. p. 79410-79452.
- Ullah E, Parwani A, Baig MM, Singh R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology--a recent scoping review. Diagn Pathol. 2024;19(1):43. doi: 10.1186/s13000-024-01464-7
- Subramanian CR, Yang DA, Khanna R. Enhancing health care communication with large language models-the role, challenges, and future directions. JAMA Network Open. 2024;7(3):e240347-e240347. doi: 10.1001/jamanetworkopen.2024.0347
- Mukherjee S, Gamble P, Ausin MS, et al. Polaris: A Safety-focused LLM Constellation Architecture for Healthcare. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2403.13313
- Abd-Alrazaq A, AlSaad R, Alhuwail D, et al. Large language models in medical education: Opportunities, challenges, and future directions. JMIR Med Educ. 2023;9(1):e48291. doi: 10.2196/48291
- Yu H, Zhou J, Li L, et al. AI Patient: Simulating Patients with EHRs and LLM Powered Agentic Workflow. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2409.18924
- Yuan T, He Z, Dong L, et al. R-Judge: Benchmarking Safety Risk Awareness for LLM Agents. arXiv. Preprint posted online 2024. doi: 10.1111/medu.15402
- Yuan T, He Z, Dong L, et al. R-Judge: Benchmarking Safety Risk Awareness for LLM Agents. arXiv [Preprint]; 2024. doi: 10.48550/arXiv.2401.10019
- Ong JCL, Chang SYH, William W, et al. Medical ethics of large language models in medicine. NEJM AI. 2024;1(7):AIra2400038. doi: 10.1056/AIra2400038
- Haltaufderheide J, Ranisch R. The ethics of ChatGPT in medicine and healthcare: A systematic review on large language models (LLMs). NPJ Digit Med. 2024;7(1):183. doi: 10.1038/s41746-024-01157-x
- Taori R, Gulrajani I, Zhang T, et al. Alpaca: A Strong,Replicable Instruction-Following Model. Center for Research on Foundation Models. 2023. Available from: https://crfm. stanford.edu/2023/03/13/alpaca.html
- Taori R, Gulrajani I, Zhang T, et al. Stanford Alpaca: An Instruction-following LLaMA model. GitHub Repository; 2023. Available from: https://github.com/tatsu-lab/ stanford_alpaca
- Gu Y, Tinn R, Cheng H, et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans Comput Healthc. 2021;3(1):1-23. doi: 10.1145/3458754
- Yasunaga M, Leskovec J, Liang P. LinkBERT: Pretraining Language Models with Document Links. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL); 2022. p. 8003-8016. doi: 10.18653/v1/2022.acl-long.551
- Venigalla A, Frankle J, Carbin M. BioMedLM: A Domain- Specific Large Language Model for Biomedical Text. Vol. 23. United States: MosaicML; 2022. p. 2.
- Luo R, Sun L, Xia Y, et al. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Brief Bioinform. 2022;23(6):bbac409. doi: 10.1093/bib/bbac409
- Tu T, Azizi S, Driess D, et al. Towards Generalist Biomedical AI. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2307.14334
- Wang G, Yang G, Du Z, Fan L, Li X. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2306.09968
- Wu C, Lin W, Zhang X, Zhang Y, Xie W, Wang Y. PMC-LLaMA: Toward building open-source language models for medicine. J Am Med Inform Assoc. 2024;31(9):1833-1843. doi: 10.1093/jamia/ocae045
- Li Y, Li Z, Zhang K, Dan R, Jiang S, Zhang Y. ChatDoctor: A medical chat model fine-tuned on a large language model Meta-AI (LLaMA) using medical domain knowledge. Cureus. 2023;15(6):e40895. doi: 10.7759/cureus.40895
- World Health Organization. Epilepsy: A Public Health Imperative. Geneva: World Health Organization; 2019.
- Annegers JF, Rocca WA, Hauser WA. Causes of epilepsy: contributions of the Rochester epidemiology project. Mayo Clin Proc. 1996;71(6):570-575. doi: 10.4065/71.6.570
- Shorvon SD. The causes of epilepsy: Changing concepts of etiology of epilepsy over the past 150 years. Epilepsia. 2011;52(6):1033-1044. doi: 10.1111/j.1528-1167.2011.03051.x
- Korenke GC, Hunneman DH, Eber S, Hanefeld F. Severe encephalopathy with epilepsy in an infant caused by subclinical maternal pernicious anaemia: Case report and review of the literature. Eur J Pediatr. 2004;163:196-201. doi: 10.1007/s00431-004-1402-4
- Pauschek J, Bernhard MK, Syrbe S, et al. Epilepsy in children and adolescents: Disease concepts, practical knowledge, and coping. Epilepsy Behav. 2016;59:77-82. doi: 10.1016/j.yebeh.2016.03.033
- Unsworth C. Living with epilepsy: Safety during home, leisure and work activities. Aust Occup Ther J. 1999;46(3):89-98. doi: 10.1046/j.1440-1630.1999.00181.x
- Aizawa A, Aramaki E, Chen B, et al. LLM-jp: A Cross- Organizational Project for the Research and Development of Fully Open Japanese LLMs. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2407.03963
- Conover M, Hayes M, Mathur A, et al. Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM; 2023. Available from: https://www.databricks.com/ blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
- Köpf A, Kilcher Y, Von Rütte D, et al. Openassistant Conversations-Democratizing Large Language Model Alignment. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS). Vol 36. 2023. p. 47669-47681.
- Papineni K, Roukos S, Ward T, Zhu WJ. BLEU: A Method for Automatic Evaluation of Machine Translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics; 2002. p. 311-318. doi: 10.3115/1073083.1073135
- Banerjee S, Lavie A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; 2005. p. 65-72. doi: 10.3115/1626355.1626389
- Lin CY. ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out. USA: Association for Computational Linguistics; 2004. p. 74-81.
- Anderson P, Fernando B, Johnson M, Gould S. SPICE: Semantic Propositional Image Caption Evaluation. In: Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, the Netherlands, October 11-14, 2016, Proceedings, Part V 14. Berlin: Springer; 2016. p. 382-398. doi: 10.1007/978-3-319-46454-1_24